Circuit Discovery
October 17, 2024 • Philip Yao, Nikhil Prakash
As interpretability researchers, we are often interested in understanding the underlying mechanisms with which deep neural networks perform various kinds of tasks. However, mechanistic interpretability works, before 2022, primarily focused on understanding some specific feature(s) or neuron(s) in the model using techniques like probing, causal probing and activation patching (or causal tracing), rather than investigating the entire end-to-end circuit responsible for performing a task (Bau et. al, Elazar et. al, Dar et. al, inter alia). The landscape started in change in 2022, when a couple works explored the entire circuit for synthetic tasks. Here, we will explore three of revelant works, but there are multiple papers that discover the underlying circuit for other tasks, such as Prakash et. al, Hanna et. al, Stefan et. al, Mathew et. al.Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
This paper was published at
ICLR 2023.
Kevin Wang Freshman at Harvard (work done at Redwood
Research)
Alexandre Variengien AI Safety Researcher at EffiSciences
(work done at Redwood Research)
Arthur Conmy Research Engineer at Google DeepMind (work
done at Redwood Research)
Buck Shlegeris CTO of Redwood Research
Jacob Steinhardt Assistant Professor at UC Berkeley
What is a circuit?
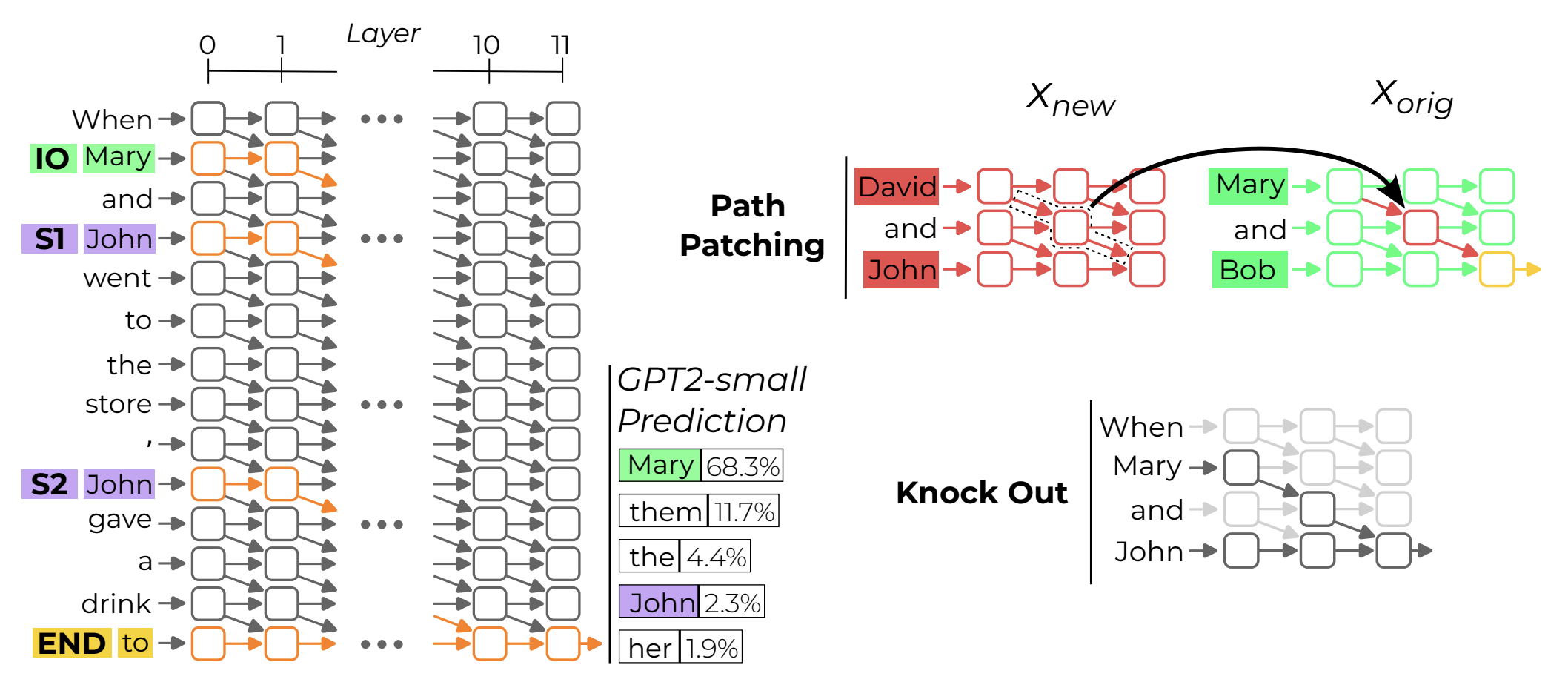
If we think of a model as a computational graph M where nodes are terms in its forward pass (neurons, attention heads, embeddings, etc.) and edges are the interactions between those terms (residual connections, attention, projections, etc.), a circuit C is a subgraph of M responsible for some behavior (such as completing the IOI task).
Experimental Setup
- The indirect object identification task sentence contains two clause: 1) Initial dependent clause, e.g. When Mary and John went to the store and 2) Main clause, e.g. John gave a bottle of milk to. The model should generate Mary as the next token. In this example, Mary is the indirect object (IO) and John is the subject (S).
- GPT-2 small a decoder-only transformer model was used for the anlaysis.
- They primarily used logit difference to quantify the performance of the model with/without any intervention.
Discovered Circuit for IOI task in GPT2-small
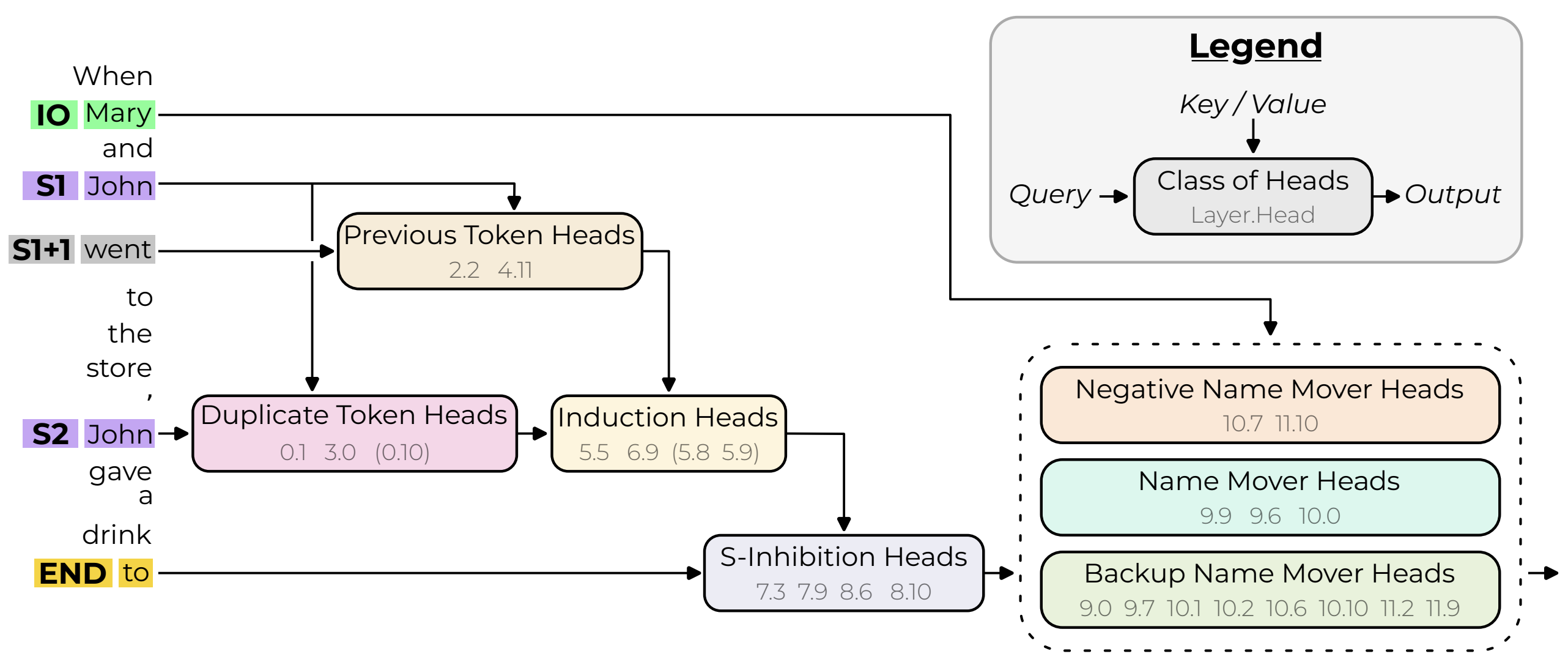
- Duplicate Token Heads: These heads occur at the S2 token and primarily attend to the S1 token. These heads write into their corresponding residual stream that this token has already occurred in the previous context.
- S-Inhibition Heads: These heads occur at the END token and attend to the S2 token. The information that these head write into the END token residual informs the query vectors of the Name Mover Heads to not attend to the S1 token.
- Name Mover Heads: These heads are also present at the END token and attend to the IO token in the main clause. They copy the name information from the IO token residual stream and dump it into the END token residual stream which gets generated as the next token.
- Previous Token Heads: These heads copy information about the token S to token S1+1, the token after S1.
- Induction Heads: These heads are present at the S2 token and attend to the S1+1 token. They perform the same function as the Duplication Token Heads.
- Backup Name Mover Heads: These are interesting set of heads. They become active only when the Name Mover Heads are knockout out using ablation.
Circuit Evaluation
Path patching algorithm is used to extract the IOI circuit present in GPT2-small model. However, how do we know that the discover circuit is indeed the correct one? Hence, this paper performs evaluation of the identified circuit using metrics like Faithfulness, Completeness, and Minimality.
Faithfulness measures how much of the model performance can be recovered by the circuit itself. Formally, it is computed using the equation \(F(M) - F(C)\), where \(F\) is the logit difference measure. They found that the identified circuit has a faithfulness score of \(0.46\), which is \(13%\) of \(F(M)=3.56\), indicating that the circuit can recover \(87\%\) of the model performance.
Completeness measures whether the circuit contains all the model components
that are involved in the computation or is it missing some important ones.
Mathematically, the Completeness is computed using the equation \(F(C
\backslash K)-F(M \backslash K)\), for every subset \(K \subset C\). If a
circuit is complete, then the value should be small. However, calculating
the metric for every possible \(K\) is computationally intractable, then the
authors use sampling techniques to get an approximation of \(K\).
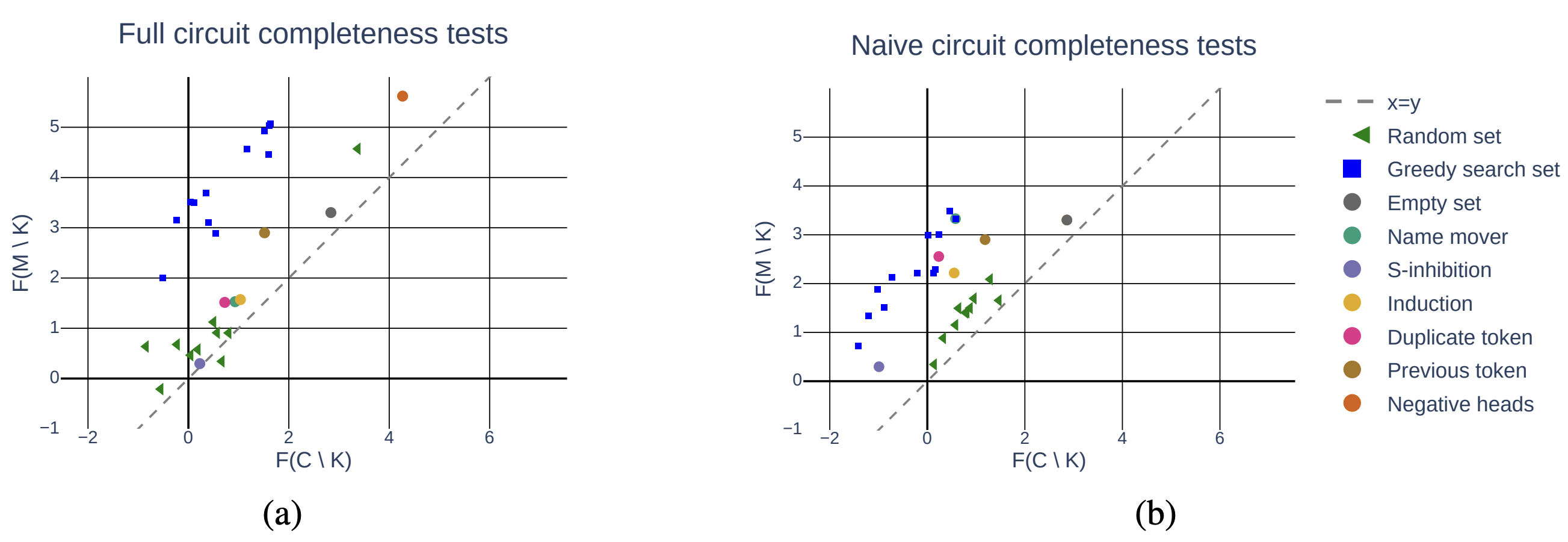
In order to check if the discovered circuit contains redundant components,
authors defined the Minimality metrics. Formally, it is defined as:
for every node \(v \in C\) there exists a subset \(K \subseteq C \backslash
\{v\}\) that has high minimality score \(|F(C \backslash (K \cup \{v\}) -
F(C \backslash K))|\). 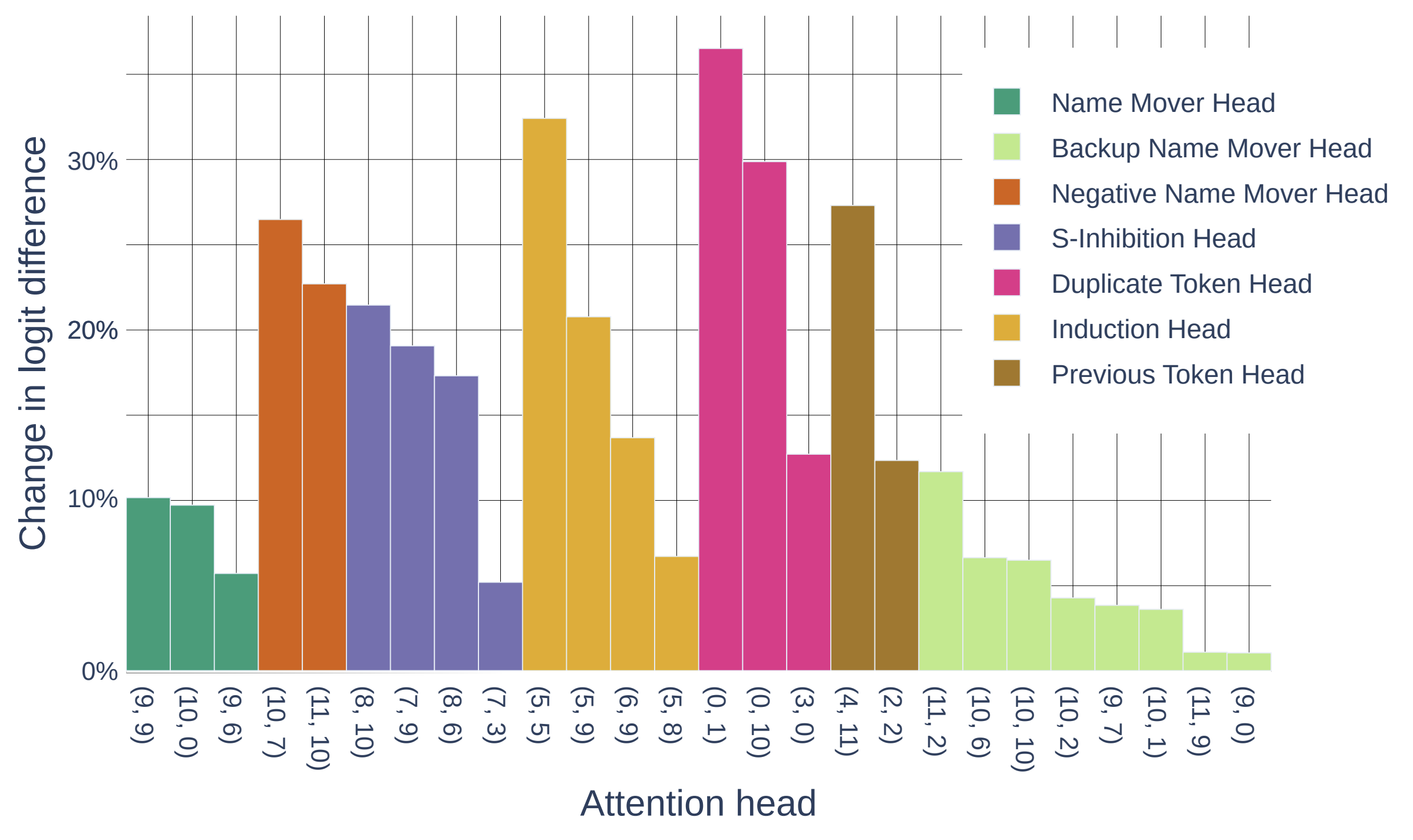
A Mechanistic Analysis of a Transformer Trained on a Symbolic Multi-StepReasoning Task
This paper was published in
ACL 2024.
Jannik Brinkmann Work done at University of Mannheim as a
PhD
Abhay Sheshadri Work done at Georgia Tech as an
Undergrad
Victor Levoso Independent Researcher
Paul Swoboda Work done at University Düsseldorf as a
Professor
Christian Bartelt Work done at University of Mannheim as a
Managing Director
The purpose of this paper is to determine how a transformer language model
solves a reasoning task. They use a binary tree traversal task to analyze
the model's behavior. The authors find that the model uses a backward
chaining algorithm to solve the task. They also show that the model uses a
deduction head to copy the source node to the current position. The authors
also show that the model uses a parallel backward chaining algorithm to
solve the task when the goal node is more than one node away. The authors
also show that the model uses a rank-one update to merge the subpaths
together. They make these discoveries by utilizing existing techniques The
article uses linear probes, activation patching, and causal scrubbing to
analyze the model's behavior. In both activation patching and causal
scrubbing, the author intervenes during the model's inference by replacing
activations of a component of interest with activations of that same
component during a different input. This impacts the model's loss and
logits. In causal scrubbing the loss is then used for this performance
metric: \(L_{CS} = (L_{scrubbed} - L_{random})/(L_{model} - L_{random}) \).
where \(L_{model}\) is the test loss of the trained model, \(L_{random}\) of
a model that outputs uniform logits, and \(L_{scrubbed}\) of the trained
model with the chosen activations resampled
The Reasoning Task
The training dataset is a binary tree \(T=(V,E)\). The model is given an
edge list, root node, and goal node. The model needs to predict the path
from the root node to the goal node. Notice that this path is unique. See
the two figures below. The first one shows the task, and the second one
shows the tree structure.
 Figure 1. A -> B is an edge from node A to node B. Edges are separated by a
comma. The goal node and root node are also included.
Figure 1. A -> B is an edge from node A to node B. Edges are separated by a
comma. The goal node and root node are also included.
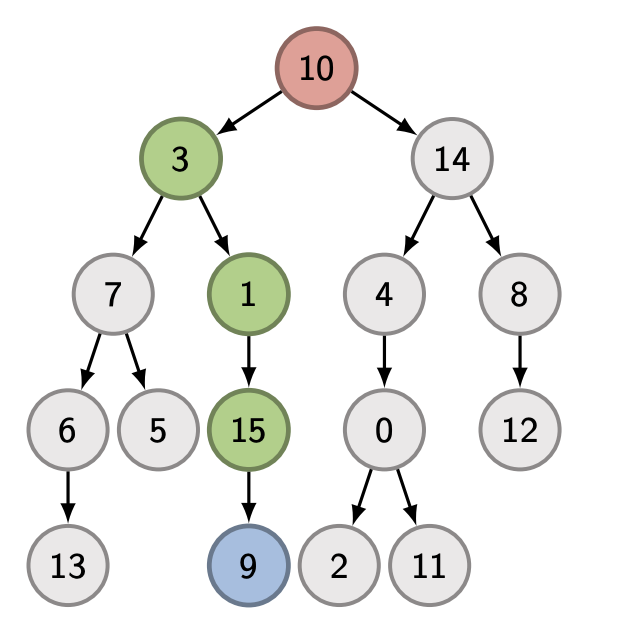
Figure 2. The red node is the root node and the blue node is the goal node.
The green nodes represent the intermediate path
Model Specifications
Authors trained a decoder-only tranformer with 6 layers, where each layer has 1 attention head and a MLP subblock. It is 1.2 million parameter, trained on 150,000 training examples. It could achive an accuracy of 99.7% on 15,000 unseen examples using the extract sequence matching metric.The Backward Chaining Algorithm
Backwards chaining is a term from symbolic AI which the model's algorithm shares similarities to. The model's algorithm is as follows:
- In the first transformer layer, for each edge [A]->[B] it copies the information from [A] into the residual stream at position [B].
- The model copies the target node [G] into the final token position.
- The authors terms the heads that perform the following operation in each layer as "deduction heads." In a given layer at the current position the model will find the source/parent node and copy it to the current position.
- This is repeated in each layer, allowing the model to traverse up the tree
However, this mechanism is limited by the number of layers present in the model, since one layer is needed to traverse a single node in the tree.
Path Merging
Authors found that there are Register Tokens that do not contain
any valuable semantic information, but the model uses these tokens as the
working memory to store information about other subpaths in the tree. These
other subpaths stored on regiter tokens are later merged at the last token
when an overlaping subpath is found for the subpath with goal node.

One-Step Lookahead
Finally, authors found another mechanism which identifies child nodes of the
current position and increases the prediction probabilities of the children
that are not leaf nodes of the tree. Attention heads in the last two layers
were primarily responsible for performing this mechanism.
 Nikhil's Opinion: Although, authors have performed causal
experiments for individual submechanism, the results would be more
convincing if they conducted a causal evaluation of mechanism responsible
for performing this task.
Nikhil's Opinion: Although, authors have performed causal
experiments for individual submechanism, the results would be more
convincing if they conducted a causal evaluation of mechanism responsible
for performing this task.
How they interpret the computations
The authors are able to use linear probes to extract both the source and
target tokens [A][B] from the residual stream activations at the position of
the target tokens after the first transformer layer.
They hypothesize that the "attention head of layer l is responsible for
writing the node that is l - 1 edges above the goal into the final token
position in the residual stream. This implies that the attention head in
layer l should be consistent across trees that share the same node l - 1
edges above the goal." They use causal scrubbing to verify this.
Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla
This paper is unpublished.
Tom Lieberum Works at DeepMind
Matthew Rahtz Works at DeepMind
János Kramár Works at DeepMind
Neel Nanda Works at DeepMind
Geoffrey Irving Works at DeepMind
Rohin Shah Works at DeepMind
Vladimir Mikulik Works at DeepMind
Motivation
This paper argues that ciruit analysis has multiple wasknesses. Two of them being: 1) Models studied in the existing literature are relatively small and 2) Most of existing works focuses on identifying model components that are causal linked to performing a particular task, but neglects the semantic information flowing through those model components. To overcome these shortcomings, this paper investigates 70B Chinchilla model on multiple-choice question answering tasks, specifically MMLU. Further, they have proposed a technique to understand the semantics of model components by compressing query, key, and value information subspaces and using it to analyse their semantics across different counterfactual examples.
Experimental Setup

- This work studies multiple-choice question-answering using a subset of the MMLU benchamark.
- Chinchilla 70B a decoder-only transformer with 80 layers and 64 attention heads is investigated.
- They use logit of the option labels as the metric for analysis.
MCQ Answering Circuit in 70B Chinchilla
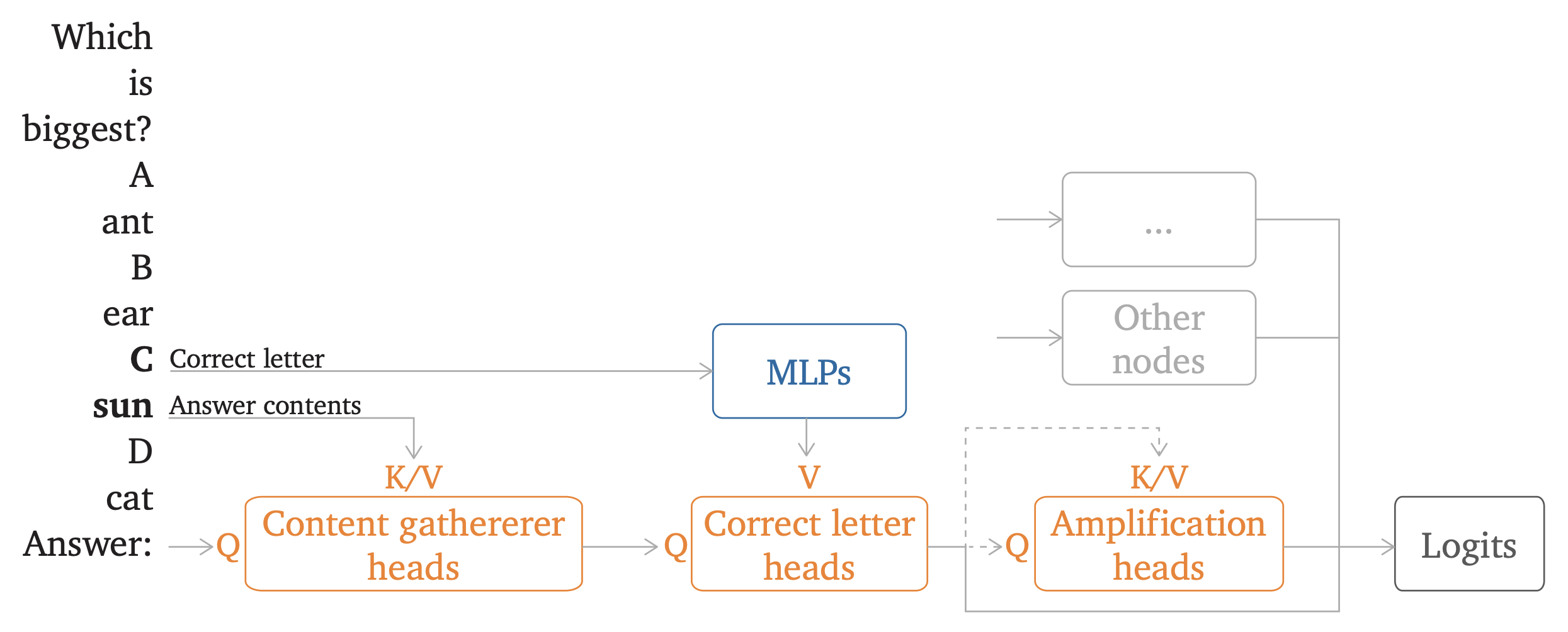 First, the authors utilize
Direct Logit Attribution to identify attention heads that have the
highest direct effect on the predicted token. Then, they selected the top 45
attention heads, since they were able to explain 80% of the option token
logits. They also showed that these heads could recover most of the model
performance and loss. To further analyse the attention heads with highest
direct effect, they visualized their value-weighted attention pattern. Based
on head's pattern, they categorized them into 4 groups:
First, the authors utilize
Direct Logit Attribution to identify attention heads that have the
highest direct effect on the predicted token. Then, they selected the top 45
attention heads, since they were able to explain 80% of the option token
logits. They also showed that these heads could recover most of the model
performance and loss. To further analyse the attention heads with highest
direct effect, they visualized their value-weighted attention pattern. Based
on head's pattern, they categorized them into 4 groups:
- Correct Letter Heads: These heads attend from the final position to the correct option label.
- Uniform Heads: These heads roughly attend to all letters.
- Single Letter Heads: These heads mostly atend to a single fixed letter.
- Amplication Heads: These heads are hypothesized to amplify the information already present in the residual stream.
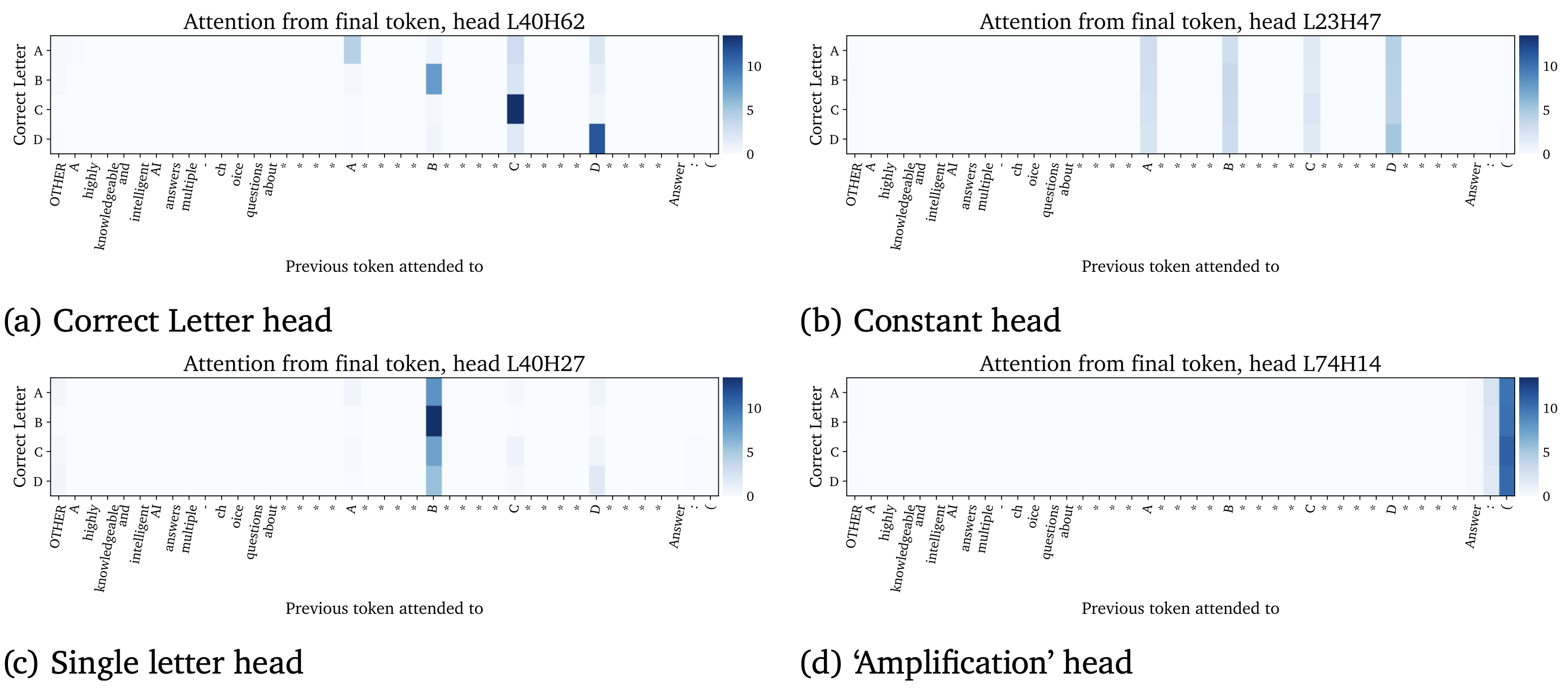 Although, these are half baked results,
it still shed light on an interesting mechanism that the model is not
passing the label information to option tokens from which the last token
could just fetch it, instead the model is first deciding on the correct
option and then finally fetching the correct label info.
Although, these are half baked results,
it still shed light on an interesting mechanism that the model is not
passing the label information to option tokens from which the last token
could just fetch it, instead the model is first deciding on the correct
option and then finally fetching the correct label info.
Semantics of Correct Letter Heads
In order to understand the semantics of the Correct Letter heads, authors
applied Singular Value Decomposition (SVD) on the residual of key and query
vectors cached across 1024 examples. They found that top-3 singular vectors
were sufficient to capture most of the variance. They found the low-rank
approximation of the key and query information had similar performance as
the full-rank ones. They projected the query and key residual onto this
3-dimensional subspace for visualization. A 3-D version can be accessed
here.
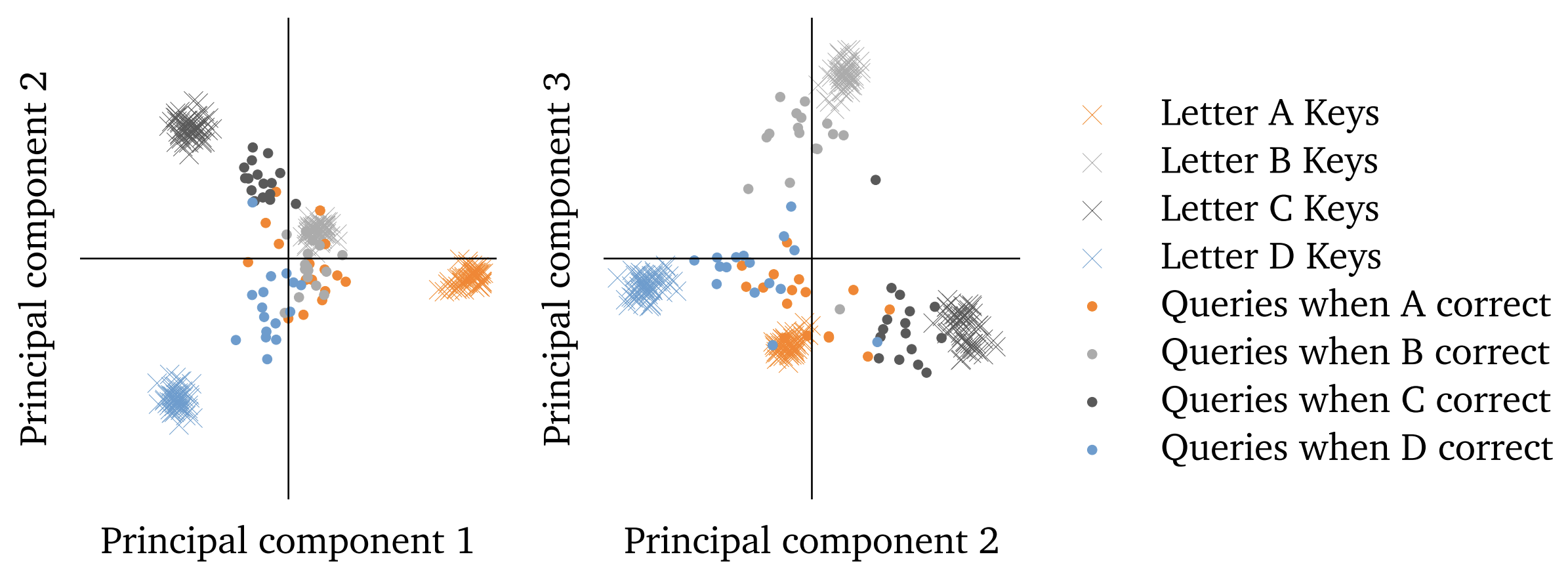 Finally, they come up with specific
mutuations of the original examples to determine which piece of information
is most critically present in the QK-subspace. They found that the subspace
primarily contains "n-th item in an enumeration" information, but also some
information that is specific to the optin tokens.
Finally, they come up with specific
mutuations of the original examples to determine which piece of information
is most critically present in the QK-subspace. They found that the subspace
primarily contains "n-th item in an enumeration" information, but also some
information that is specific to the optin tokens.
By utilizing these investigating on the semantics of the Correct Letter
heads, the authors were able to come up with the following psuedocode for
the functionality of these heads. 
Code Resources
Try this colab notebook to investigate the IOI circuit with GPT2-small yourself. You can use it to perform direct logit attribution, activation patching and attention pattern visualization to understand the flow of information. This notebook has been inspired from Neel Nanda's exploratory analysis demo.