In-context Learning
November 6, 2024 • David Atkinson, Sri Harsha
"In-context learning" (ICL) identifies to a phenomenon in which a language model shows decreasing loss as one or more task examples are added to its context window. The modern era of ICL begins with Brown et al., (2020) who extend the multi-task learning (Caruana, 1997), scaling law (Kaplan et al., 2020; Hestness et al., 2017), and meta-learning (Finn et al., 2017) literatures with a massively scaled version of GPT-2 (Radford et al., 2019). Although GPT-2 showed early signs of ICL, the new model, GPT-3, displays state-of-the-art performance on a wide variety of NLP benchmarks, without relying on any finetuning.
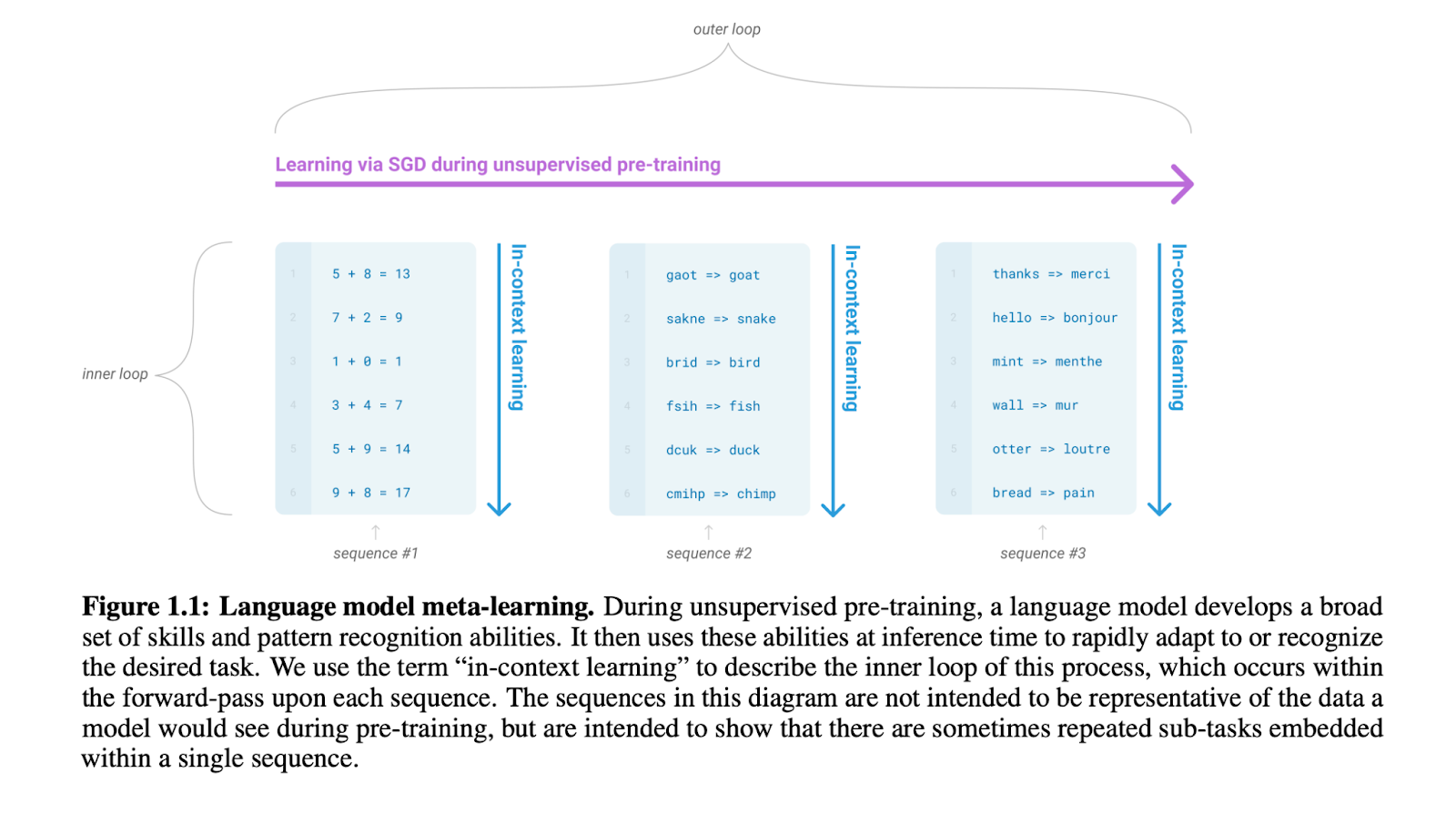
Figure from Brown et al., 2020
The ICL literature has expanded rapidly since the release of GPT-3, with investigations into training strategies, prompt tuning techniques, scoring function optimization, and applications beyond text to areas like computer vision and speech synthesis. (For a full survey, see Dong et al., (2024).) Of particular relevance to us is the induction heads phenomenon, which we've covered in previous weeks.
This week, we'll discuss two papers which attempt to characterize how ICL works in large language models.
Function Vectors in Large Language Models
This paper was published at ICLR 2024 by a group of researchers from Northeastern University:
- Eric Todd, a PhD student at Northeastern.
- Millicent Li, a PhD student at Northeastern.
- Arnab Sen Sharma, a PhD student at Northeastern.
- Aaron Mueller, a postdoc at Northeastern and soon to be Assistant Professor at Boston University.
- Byron Wallace, an Associate Professor at Northeastern, whose previous paper (Jain and Wallace, 2019) on the (un-)interpretability of attention patterns motivated the current work.
- David Bau, an Assistant Professor at Northeastern, whose most relevant paper is maybe Meng et al., (2022).
The authors make a surprising finding: within transformer language models, there exist vector representations (which they call "function vectors", or "FVs") of a wide range of in-context learning tasks. These vectors can be extracted from a small number of attention heads and, when inserted into new contexts, trigger the execution of specific tasks.
Finding Function Vectors
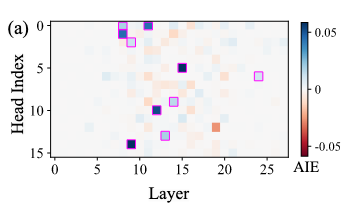
The authors use causal mediation analysis—seen previously in Meng et al., (2022) to identify the components of the model most responsible for ICL. Formally, given the output \(a_{\ell j}\) of attention head \(j\) from layer \(\ell\), run on a prompt \(p_i^t\) drawn from task \(t\), the authors calculate the mean output of the head across all prompts in the task: \[\bar{a}^t_{\ell j} = \frac{1}{|P_t|}\sum_{p^t_i} a_{\ell j}(p^t_i)\] This allows them to use the causal tracing framework to identify the average indirect effect of the head on the task (where the "corrupted" input, in this case, is an ICL prompt with randomized labels).
Function Vectors
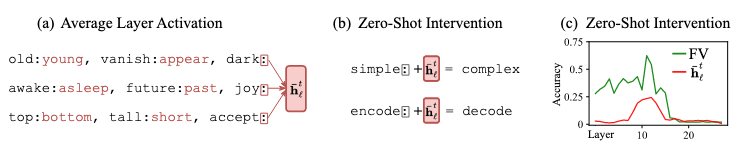
To calculate the function vector for a task \(t\), then, the authors take the mean sum of the outputs from the most causally important attention heads \(A\) over all tasks: \[v_t = \sum_{a_{\ell j} \in A} \bar{a}^t_{\ell j}\]
This vector is then added to the model's residual stream at a chosen layer.
Key Properties

- Robustness: FVs work across a range of contexts, including zero-shot and on natural text that bears no resemblance to the original ICL format
- Scaling: The phenomenon appears across model sizes, from 6B to 70B parameters
- Composability: FVs can sometimes be combined through vector arithmetic to create new composite functions

More Than Just Word Embeddings
How do FVs work? One hypothesis is that they encode and promote a subset of the task's output vocabulary. On an English-to-Spanish task, for example, they might promote Spanish words similar to ones seen before. However, the authors present several lines of evidence that suggest FVs must be doing more than this:
- The efficacy of FVs drops off sharply in later layers, suggesting that the functions they encode are not representable as simple offsets.
- They can encode cyclic mappings (like antonyms) that cannot be represented as vector offsets.
- If you use the logit lens to look at FVs, there are often cases where the relevant vocabulary is strongly promoted. However, the authors show that the vocabularly distribution alone can't explain the performance of FVs: there are vectors that decode to the same vocabulary distribution which have very different effects.
What learning algorithm is in-context learning? Investigations with linear models
The paperBackground and context
This study investigates the theoretical capabilities of transformer decoders to implement learning algorithms, particularly focusing on linear regression problems. The analysis reveals that transformers require only a modest number of layers and hidden units to train linear models. Specifically, for d-dimensional regression problems, a transformer can perform a single step of gradient descent with a hidden size proportional to O(d) and constant depth. Additionally, with a hidden size of O(d^2) and constant depth, transformers can update a ridge regression solution to incorporate new observations. Intuitively, multiple steps of these algorithms can be implemented by stacking more layers.
The empirical investigation begins by constructing linear regression problems where the learner's behavior is under-determined by the training data. This setup allows for different valid learning rules to produce different predictions on held-out data. The results show that model predictions closely match those made by existing predictors (such as gradient descent and ridge regression). Moreover, as model depth and training set noise vary, the predictions transition between different predictors, eventually behaving like Bayesian predictors at larger hidden sizes and depths.
Preliminary experiments demonstrate how model predictions are computed algorithmically in transformer-based in-context learners. These experiments show that important intermediate quantities—such as parameter vectors and moment matrices—which are typically computed by learning algorithms for linear models, can be decoded from the hidden activations of in-context learners. This suggests that transformers trained for in-context learning may rediscover and implement standard estimation algorithms implicitly through their internal activations.
Experiment
For a transformer-based model to solve Linear regression by implementing an explicit learning algorithm, that learning algorithm must be implementable via attention and feed forward with some fixed choice of transformer parameters θ. We prove constructively that such parameterizations exist, giving concrete implementations of two standard learning algorithms. These proofs yield upper bounds on how many layers and hidden units suffice to implement (though not necessarily learn) each algorithm.
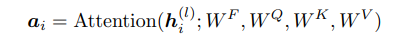

Gradient Descent

w0: The updated weight vector after applying one step of gradient descent.
w: The current weight vector (parameters) of the model before the update.
α: The learning rate
xi : Input feature vector for example
yi: Target value for example i

Closed-form regression
Another way to solve the linear regression problem is to directly compute the closed-form solution . This is somewhat challenging computationally, as it requires inverting the regularized covariance matrix
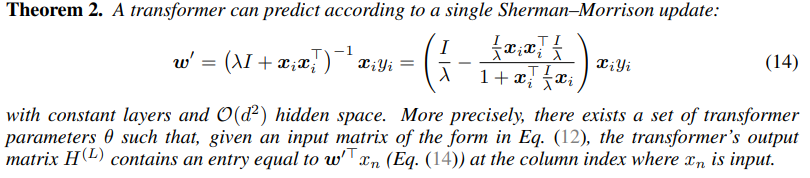
Behavior metrics
The Squared Prediction Difference (SPD) is a metric used to quantify how much two different learning algorithms or predictors disagree in their predictions. It measures the squared difference between the predictions made by two algorithms on the same input data.
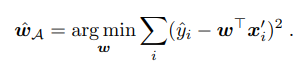
The Implicit Linear Weight Difference (ILWD) is a metric used to quantify the difference between the weight vectors (or parameters) implied by different learning algorithms when solving a linear regression problem. This metric helps compare how closely two predictors agree in terms of the parameters they learn, rather than just their predictions.
Experiment
The training objective in the paper is designed to train a transformer model to perform in-context learning (ICL). In ICL, the model is trained to learn how to predict outputs for new inputs based on a sequence of input-output pairs provided in the context, without updating its parameters. The following is the training objective.
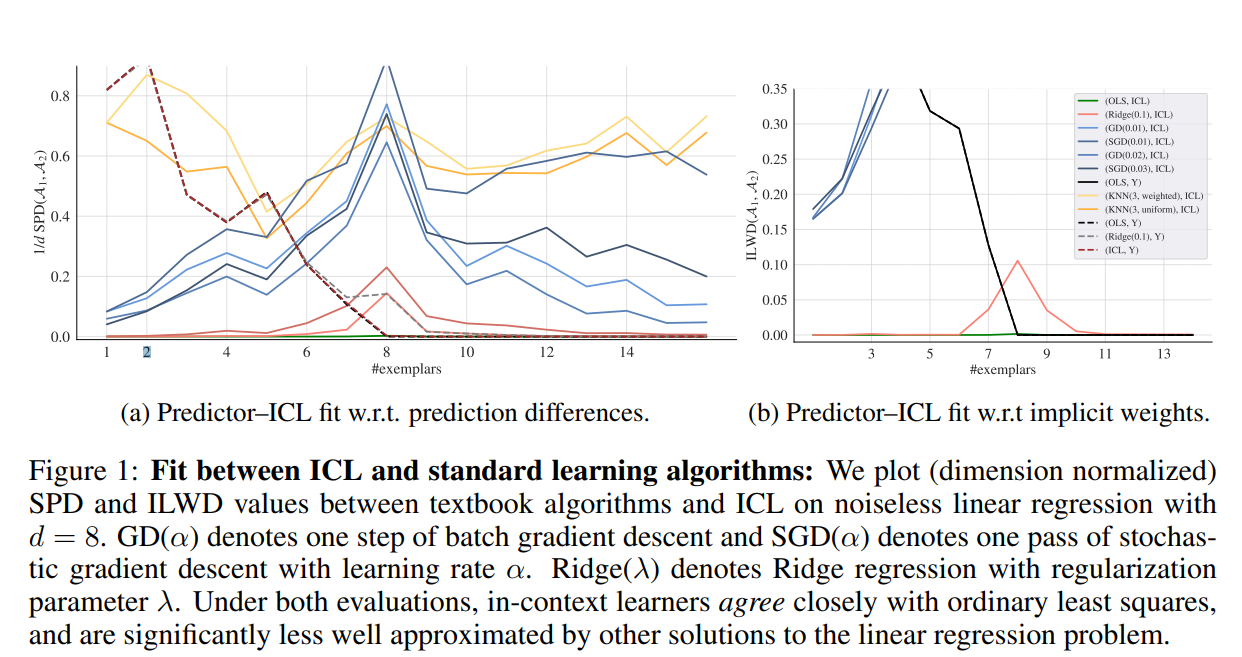
Transformer decoder autoregressively on the training objective. For all experiments, we perform a hyperparameter search over depth L ∈ (1, 2, 4, 8, 12, 16), hidden size W ∈ (16, 32, 64, 256, 512, 1024) and heads M ∈ (1, 2, 4, 8). Other hyper-parameters are noted in Appendix D. For our main experiments, we found that L = 16, H = 512, M = 4 minimized loss on a validation set. We follow the training guidelines in Garg et al. (2022), and trained models for 500, 000 iterations, with each in context dataset consisting of 40 (x, y) pairs.
Results and conclusion
ICL Matches Ordinary Least Squares (OLS) Predictions on Noiseless Datasets. In noiseless datasets, there is no random error in the data, so OLS provides an exact solution. The experiment shows that ICL can replicate this behavior, meaning that transformers trained for ICL can implicitly implement OLS like predictions without explicitly being programmed to do so.
ICL was compared with other textbook predictors like k-nearest neighbors, One-pass stochastic gradient descent, One-step batch gradient descent, Ridge regression. ICL matches OLS predictions more closely than any other especially in noiseless settings.
Squared Prediction Difference (SPD) and Implicit Linear Weight Difference (ILWD) metrics were used to quantify how closely ICL predictions matched those of other algorithms. Both metrics indicated that ICL predictions were very similar to those of OLS, with small squared errors (less than 0.01), while other predictors showed much larger differences.
When noise or uncertainty is introduced into the dataset, ICL behaves like a minimum Bayes risk predictor, which is a Bayesian approach that minimizes expected loss under uncertainty. The experiments show that as noise increases, ICL transitions from behaving like OLS to behaving like a Bayesian predictor, which suggests that transformers can adapt their predictions based on the level of uncertainty in the data.

When there are fewer examples than input dimensions (i.e., underdetermined problems), ICL selects the minimum-norm solution, which is consistent with OLS behavior. In underdetermined problems, there are infinitely many solutions that can fit the data exactly. OLS selects the solution with the smallest norm (or smallest weight vector). The experiment shows that ICL also selects this minimum-norm solution when faced with ambiguous or underdetermined datasets.
Probing experiment
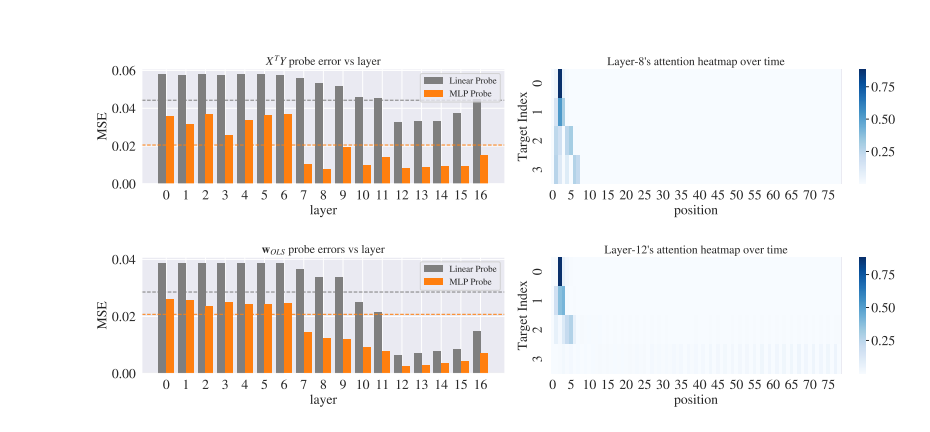
Transformer-based in-context learners (ICL) encode meaningful intermediate quantities, such as weight vectors and moment matrices, during their prediction process. These quantities are typically computed by traditional learning algorithms like gradient descent or ridge regression when solving linear regression problems. The experiment's goal is to determine if transformers, while performing ICL, internally compute and store these key quantities in their hidden activations. To test this, a transformer is trained on sequences of input-output pairs (exemplars) and probed its internal activations at various layers to see if these intermediate values could be decoded.
Probing for Weight Vectors: To determine whether the weight vectors (the parameters of the linear model) could be decoded from the transformer’s hidden states. They applied a linear decoder to the hidden activations of the transformer at various layers. This decoder attempts to extract weight vectors that are similar to those computed by standard learning algorithms like ordinary least squares (OLS) or ridge regression. The experiment showed that weight vectors could indeed be decoded from later layers of the transformer. This suggests that transformers internally compute and store weight vectors during in-context learning, even though they are not explicitly programmed to do so.
Probing for Moment Matrices: probed for moment matrices, which capture relationships between input features (e.g., covariance matrices in linear regression). Similar to the weight vector probing, a linear decoder was applied to the hidden activations to see if moment matrices could be extracted. Moment matrices were successfully decoded from certain layers of the transformer, indicating that transformers also compute these important intermediate quantities during in-context learning.
Code Resources
For function vectors, see this notebook from Callum McDougal and the ARENA team (with associated answers).