Lenses
October 01, 2024 • Prajnan Goswami, Ritik Bompilwar
The launch of GPT-3 by Brown et al. (2020) marked a turning point, drawing widespread attention to the potential of Large Language Models (LLMs) and their applications such as ChatGPT, Copilot, etc. In parallel, diffusion models emerged as a powerful tool for synthesizing high-fidelity images as demonstrated by Ho et al.(2020) and Rombach et al. (2021). These new generative AI approaches led to a paradigm shift in scaling up models and data to extract more performance.
Scaling Trends in the Evolution of Generative Models (In a Nutshell)
A study by Kaplan et al. highlights the significance of model size, dataset scale, and compute used in training. Their analysis indicates that larger models will continue to perform better. In the table below, we can clearly observe how these models have scaled up over time:
| Year | Model | Parameters |
|---|---|---|
| 2019 | GPT-2 | 1.5 billion |
| 2020 | GPT-3 | 175 billion |
| 2020 | Denoising Diffusion Probabilistic Models | 256 million |
| 2021 | Stable Diffusion | 1 billion |
| 2023 | Stable Diffusion XL | 3.5 billion |
| 2024 | Llama 3.1 | 405 billion |
Looking Through the Lens of Interpretability
Although scaling up these approaches has led to significant capabilities and performance improvements, understanding the hidden representations and interpret how the model progresses toward generating its final output through all the intermediate layers remains a challenge.
For example, in the paper 'Locating and Editing Factual Associations in GPT', Meng et al. demonstrates that when a harmful context is provided to a GPT model, the model knows the correct answer but imitates and states the wrong one". Hence, in such scenarios it is critical to identify the components in these GPT-like models that causes incorrect imitations to emerge over the course of the model's processing (Halawi et al., Overthinking the Truth).
Now what if we apply linear probing from the previous chapter to a Large Language Model(LLM). The process would involve training a separate probe for each layer. Additionally, each probe would require a predefined set of labels (e.g., sentiment, part-of-speech tags etc.) to evaluate specific types of information the model might encode. In other words, the results may not reflect the model's internal working for the original task it was trained on.
To address these challenges, we need a mechanism to directly look at (👀 🔎) the hidden representations of a large scale generative AI model without any external probes.
This chapter will focus on some of these technqiues which offer a clearer view of how these large-scale model processes and represents information at each layer.
Visualizing GPT through a Lens 🔎
The first attempt on how to interpret the internal workings of a
GPT-like model was introduced in an anonymous blog post
Interpreting GPT: the logit lens — LessWrong.
The idea was fairly straightforward. In large language models(LLMs), predictions are formed in a series
of steps across multiple Transformer layers. The Logit Lens "peeks 👀" at these
intermediate stages by taking the intermediate outputs at each layer and projecting
them directly into the vocabulary space. In other words, the intermediate output from
different layers is passed through the same output head that the final layer uses to
predict the next token as shown in the figure below.
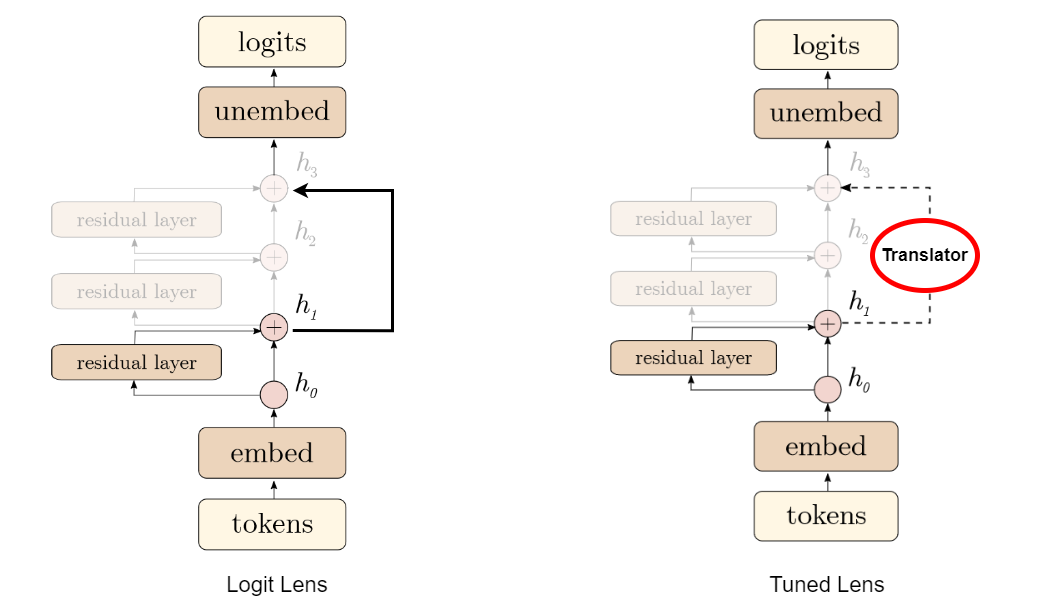
What makes this approach special is that, rather then relying on external probes, Logit lens uses its own prediction head to interpret the hidden representations. By doing so, we can easily track the evolution of the model's understanding at every processing stage. That being said, this first attemt had few limitations.
Belrose et al. highlighted three specific limitations of Logit Lens in their paper Eliciting Latent Predictions from Transformers with the Tuned Lens.
- Logit Lens didn’t work well for other models such as BLOOM (Scao et al.) and OPT 125M (Zhang et al.).
-
It is biased towards some vocabulary until the final layer of GPT.
In simple terms, this means that the output of the intervention layer
is skewed towards certain words when compared to the final output of the
GPT model itself.
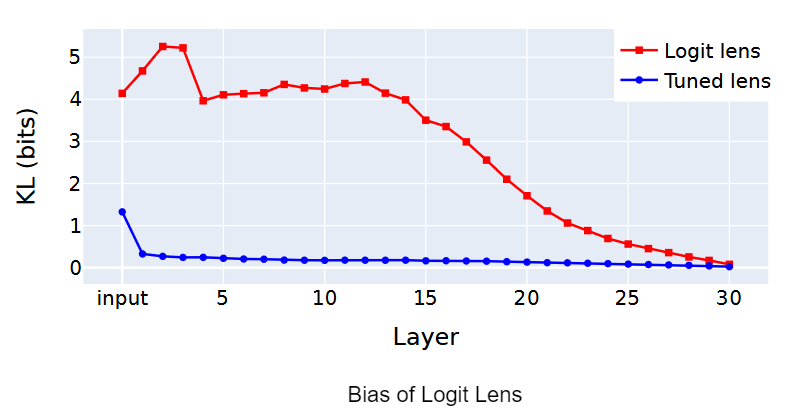
The x-axis represents the different layers of the neural network, and the y-axis represents the difference (in bits) between the output of the method and the final output of the model.
- And finally Logit Lens is prone to representational drift. What it really means is that the hidden representations at the intervention layer does not align with the expected input representations of the final layer.
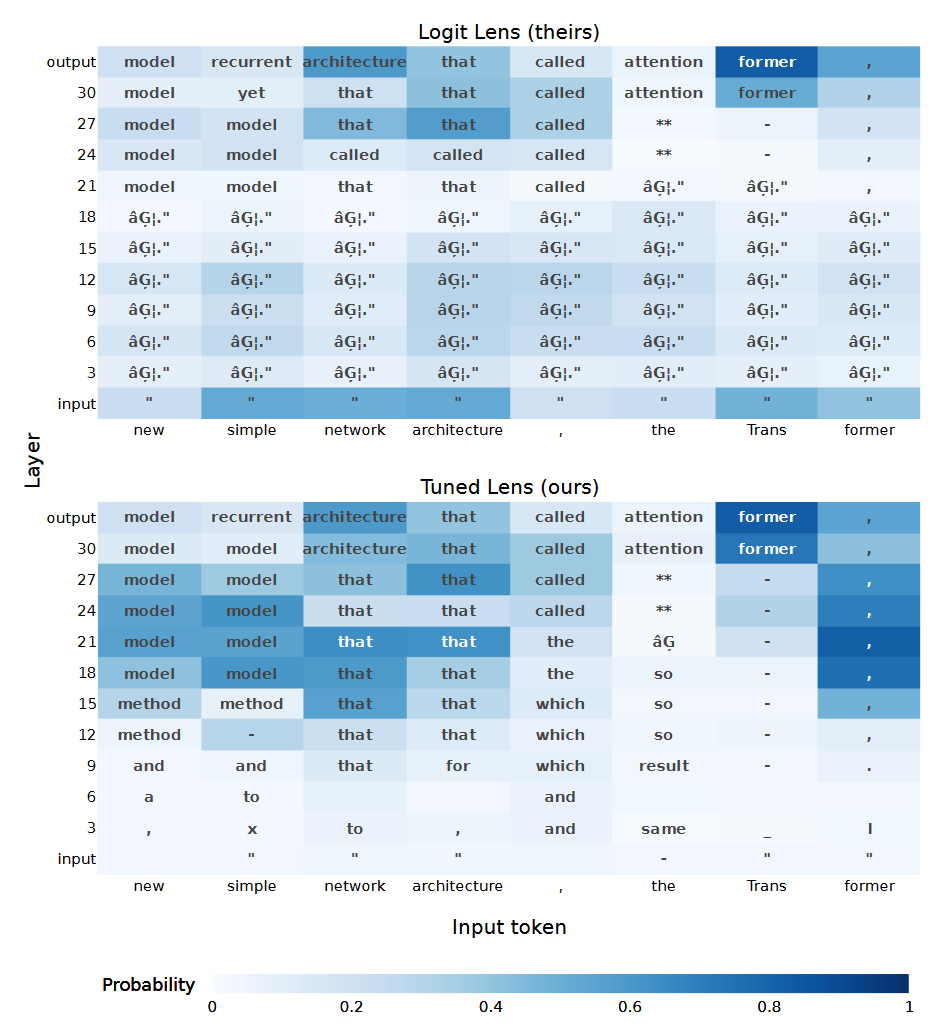
With this adjustment made to the Logit Lens, the Tuned Lens showed
more meaningful results starting from the early layers of the model
as shown in Figure 3.
Patchscopes 🩺
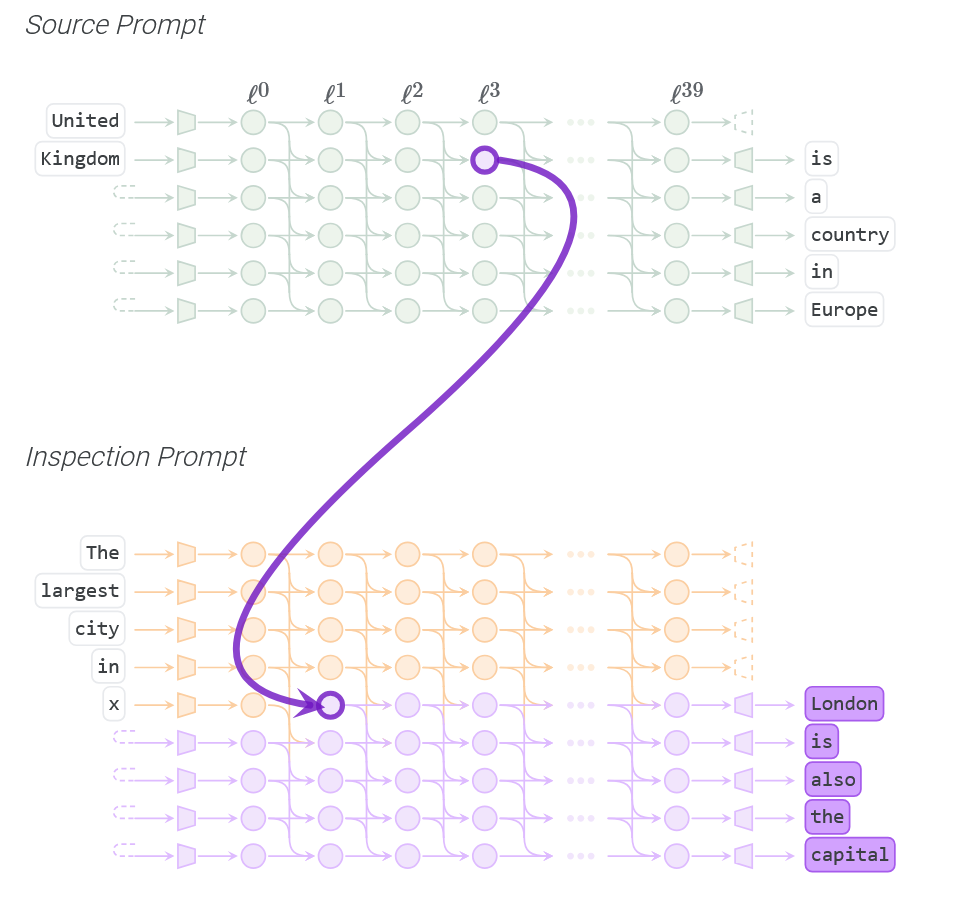
Influenced by the efforts of Logit Lens and Tuned Lens Ghandeharioun et al. , presented a framework to decode the internal working of LLMs in a human interpretable format. The key idea is to use a target LLM to explain the internal working of the LLM under study. For example, in the figure above, we are interested in the hidden representation of layer 4 that encodes "UK". This can be interpreted using an inspecting prompt. We replace x in the inspection prompt with the hidden state and continue generating the output in the target LLM. The results of the target LLM indicates that 'layer 4' indeed resolves UK as a country. With this approach the authors provides several applications of the framework to answer a wide range of questions about an LLM's computation. We highly recommend reading the interactive blog to understand the framework's capability.
Prajnan's opinion: Overall this technique is cleary layed out in the paper as well as the interactive blog with lots of great examples. And the cherry on top is that it does not require further training of additional parameters. That being said, in scenarios where the results are not interpretable, it might be challenging to identify if the source or the target model or the inspection prompt itself was responsible for misinterpreting the hidden state. One way to validate the Patchscope's interpretations might be to patch the hidden state with multiple target models.
Other Lens Approaches for LLMs
There are several other approaches that extends Logit Lens and Future Lens toward interpretability of Generative Language Models. Some of these include Locating and Editing Factual Associations in GPT by Meng et al., Overthinking the Truth: Understanding how Language Models Process False Demonstrations by Halawi et al., SelfIE: Self-Interpretation of Large Language Model Embeddings by Chen et al., and Future Lens: Anticipating Subsequent Tokens from a Single Hidden State by Pal et al.Diffusion Lens
Diffusion based text to image models have been a game changer in the field of generative AI. Such text-to-image (T2I) models consist of a of two main components: the text encoder and the diffusion model. The text encoder takes in the text input and encodes it into a latent space representation, while the diffusion model takes in this latent space representation and generates an image. However the process by which the encoder produces the text representation is still not well understood.
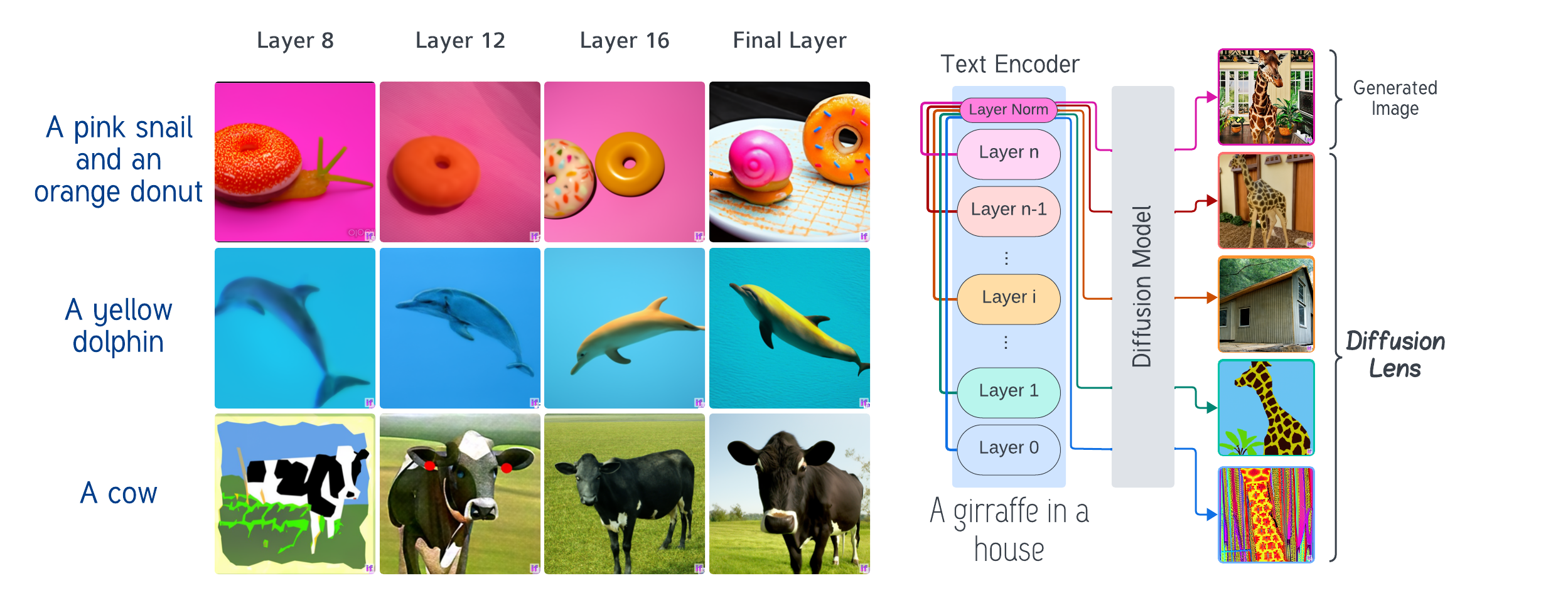
Toker et al. (2024) proposed Diffusion Lens to visualize the intermediate representations in the text encoder of T2I models. Authors examined the computational process of the text encoder in the Stable Diffusion (Rombach et al., 2022) and Deep Floyd (StabilityAI, 2023) to analyse the model's capabilty of conceptual combination and it's memory retrieval process. The process involves:
- Layer-wise Visualization: At each layer of the text encoder, the intermediate outputs are extracted and projected into a human-interpretable space. This projection allows us to observe how textual representations evolve, revealing the gradual construction of semantic meaning.
- Conceptual Mapping: By analyzing the latent representations, the Diffusion Lens identifies how individual concepts from the input prompt are encoded and combined. This mapping highlights the model's ability to understand and synthesize complex instructions.
- Memory Retrieval Analysis: Diffusion Lens assesses how the model retrieves relevant information from its training data. By examining the activation patterns across layers, we can infer the mechanisms behind the model's knowledge retrieval and application.
Key Insights from the Analysis

Conceptual Combination Analysis
-
Complex prompts require more computation to achieve a faithful representation compared to simpler prompts.
-
Complex representations are built gradually. The early layer represenations are like "bag of concepts", that encode concepts separately or together without capturing their true relationship.
Subsequent layers encodes the relationship between the concepts more accurately.
-
The order in which the objects during computation is influence by their linear or syntactical precedence in the prompt.
SD's CLIP (Radford et al., 2021) encoder tends to reflect linear precedence, while Deep Floyd's T5 (Raffel et al., 2019) encoder reflects syntactical precedence.
Memory Retrieval Analysis
-
Common concepts like "Kangaroo" emerge in early layers while less common concepts like "Dik-dik" (an animal) gradually emerge in subsequent layers, with most accurate represenation predominantly appearing in upper layers.
-
Finer details materializes in the later layers.
-
Knowledge retrieval is gradual, unfolds as the computation progresses. This observation contrdicts from prior research (Arad et al., 2023) on knowledge encoding in languagae models which suggests that the knowledge is encoded in specific layers.
-
Memory retrieval patterns in Deep Floyd's T5 encoder are different from Stable Diffusion's CLIP encoder. T5's memory retrival exhibits a more incremental pattern compared to CLIP's.
Ritik's Take: I found the results from the Diffusion Lens really fascinating.
I felt the paper provides valuable insights on how the text is transformed into visual content, and the role text encoders play in it.
But I feel the paper should have also given insights on the outputs fom the diffusion layers, where the image generation actually happens.
I think it fell short to convince how the encoded information is actually translated into the final visual output. The paper does open up pathways
for a DiffusionLens that actually helps see output from the diffusion layers.
Colab Notebook and other Code Resources
-
Here is an
interactive Colab demo that compares Logit Lens and Tuned Lens. You can ignore the 'pyarrow 17.0.0'
dependency error and execute the subsequent notebook cells.
-
A demo of Diffusion Lens can be viewed here,
where you can provide a text prompt and inspect the images generated from several layers of the Text Encoder.
- Common concepts like "Kangaroo" emerge in early layers while less common concepts like "Dik-dik" (an animal) gradually emerge in subsequent layers, with most accurate represenation predominantly appearing in upper layers.
- Finer details materializes in the later layers.
- Knowledge retrieval is gradual, unfolds as the computation progresses. This observation contrdicts from prior research (Arad et al., 2023) on knowledge encoding in languagae models which suggests that the knowledge is encoded in specific layers.
- Memory retrieval patterns in Deep Floyd's T5 encoder are different from Stable Diffusion's CLIP encoder. T5's memory retrival exhibits a more incremental pattern compared to CLIP's.
Ritik's Take: I found the results from the Diffusion Lens really fascinating. I felt the paper provides valuable insights on how the text is transformed into visual content, and the role text encoders play in it. But I feel the paper should have also given insights on the outputs fom the diffusion layers, where the image generation actually happens. I think it fell short to convince how the encoded information is actually translated into the final visual output. The paper does open up pathways for a DiffusionLens that actually helps see output from the diffusion layers.
Colab Notebook and other Code Resources
- Here is an interactive Colab demo that compares Logit Lens and Tuned Lens. You can ignore the 'pyarrow 17.0.0' dependency error and execute the subsequent notebook cells.
- A demo of Diffusion Lens can be viewed here, where you can provide a text prompt and inspect the images generated from several layers of the Text Encoder.